Elasticsearch值_type
_type产生的历史原因
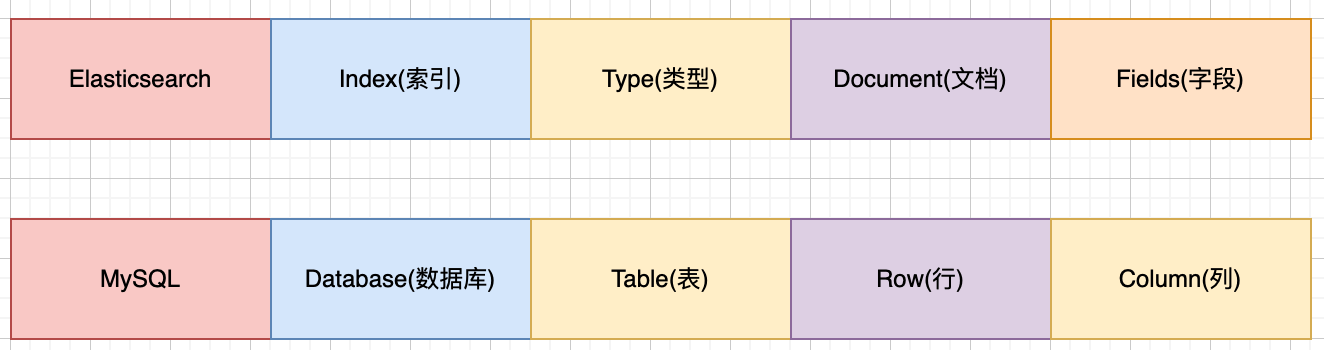
Index:索引。复数是Indices。类似的数据放在一个索引,非类似的数据放不同索引, 一个索引也可以理解成一个关系型数据库;
Type:类型。
Document:文档。保存在某个index下,某种type的一个数据document,文档是json格式的,document就像是mysql中的某个table里面的内容,每一行对应的列叫属性。
可以将ES中的三个概念和MySQL类比:
- Index对应MySQL中的Database。
Type对应MySQL中的Table。- Document对应MySQL中表的记录。 整体对比如下图所示
从Elasticsearch的第一个版本开始,每个文档(Document)都存储在一个索引(Index)中,并分配一个映射类型(Type)。映射类型(Type)用于表示被索引的文档或实体的类型,例如twitter索引可能有一个user类型和一个tweet类型。
每一个映射类型(Type)都可以有他自己的属性字段,因为,user映射类型可能有一个full_name属性字段,一个user_name属性字段,和一个email属性字段。而tweet映射类型可能有一个content属性字段,一个tweeted_at属性字段,像user映射类型一样,也可以有一个user_name属性字段。
每个文档(Document)都有一个包含类型名称的_type元数据字段,并且可以通过在URL中指定类型名称来限制搜索到一个或多个类型:
GET twitter/user,tweet/_search
{
"query": {
"match": {
"user_name": "kimchy"
}
}
}
映射类型(Type)字段与文档(Document)的_id相结合,生成一个_uid字段,因此具有相同_id的不同映射类型(Type)的文档(Document)可以存在于单个索引中。
为什么要删除映射类型(Type)
最初,我们谈到“索引(Index)”类似于SQL数据库中的“数据库(Database)”,而“映射类型(Type)”相当于“表(Table)”。 这并不是一个很好的类比,会导致错误的假设。在SQL数据库中,表是相互独立的。一个表中的列与另一个表中具有相同名称的列无关。对于映射类型中的字段则不是这样。 在Elasticsearch索引中,在不同映射类型中具有相同名称的字段在内部由相同的Lucene字段支持。换句话说,使用上面的示例,user映射类型中的user_name字段与tweet映射类型中的user_name字段存储在完全相同的字段中,并且两个user_name字段必须在这两种类型中具有相同的映射(定义)。 例如,当您希望在同一索引中deleted在一个映射类型中是日期字段,在另一种映射类型是布尔字段时,这可能会导致失败。最重要的是,在同一个索引中存储具有很少或没有共同字段的不同实体会导致数据稀疏,并干扰Lucene有效压缩文档的能力。
映射类型的替代方案
每个文档(Document)创建一个索引一个映射类型
第一种选择是为每个文档类型提供一个索引。可以将tweet存储在tweets索引中,users存储在user索引中,而不是将tweet和users存储在单个twitter索引中。索引之间是完全独立的,因此索引之间不会有字段类型冲突。
这种方法有两个好处:
- 数据可能是密集的,因此能更好的使用Lucene中的压缩技术。
- 在全文搜索中用于评分的术语统计数据可能更准确,因为同一索引中的所有文档都代表一个实体。
每个索引可以根据它将包含的文档数量适当地调整大小:可以为user使用较少数量的主分片,而为twitter使用较多数量的主分片。
自定义Type字段
当然,集群中可以存在的主分片数量是有限的,因此您可能不希望为了只有几千个文档的集合而浪费整个分片。在这种情况下,您可以实现自己的自定义类型字段,其工作方式与旧的_type类似。
让我们以上面的user/tweet为例。最初,工作流看起来是这样的:
PUT twitter
{
"mappings": {
"user": {
"properties": {
"name": { "type": "text" },
"user_name": { "type": "keyword" },
"email": { "type": "keyword" }
}
},
"tweet": {
"properties": {
"content": { "type": "text" },
"user_name": { "type": "keyword" },
"tweeted_at": { "type": "date" }
}
}
}
}
PUT twitter/user/kimchy
{
"name": "Shay Banon",
"user_name": "kimchy",
"email": "shay@kimchy.com"
}
PUT twitter/tweet/1
{
"user_name": "kimchy",
"tweeted_at": "2017-10-24T09:00:00Z",
"content": "Types are going away"
}
GET twitter/tweet/_search
{
"query": {
"match": {
"user_name": "kimchy"
}
}
}
我们可以通过添加一个自定义类型字段来达到同样的效果,如下所示:
PUT twitter
{
"mappings": {
"_doc": {
"properties": {
"type": { "type": "keyword" },
"name": { "type": "text" },
"user_name": { "type": "keyword" },
"email": { "type": "keyword" },
"content": { "type": "text" },
"tweeted_at": { "type": "date" }
}
}
}
}
PUT twitter/_doc/user-kimchy
{
"type": "user",
"name": "Shay Banon",
"user_name": "kimchy",
"email": "shay@kimchy.com"
}
PUT twitter/_doc/tweet-1
{
"type": "tweet",
"user_name": "kimchy",
"tweeted_at": "2017-10-24T09:00:00Z",
"content": "Types are going away"
}
GET twitter/_search
{
"query": {
"bool": {
"must": {
"match": {
"user_name": "kimchy"
}
},
"filter": {
"match": {
"type": "tweet"
}
}
}
}
}
显式type字段代替隐式_type字段。
删除映射类型计划
Elasticsearch 5.6.0
- 设置 index.mapping.single_type: true 将启用每个索引单一类型的行为,这将在Elasticsearch6.0中强制执行。
Elasticsearch 6.x
- 在5.x创建的索引还是能够在6.x版本运行,就像在5.x版本上一样。
- 6.x创建的索引,每个索引只有一个单一类型。该类型可以使用任何名称,但只能有一个名称。首选类型名是_doc,这样子,索引APIs的路径将会与7.0中的相同:PUT {index}/_doc/{id}和POST {index}/_doc
- _type名称不能再与_id组合组成_uid字段。_uid字段已经成为_id字段的别名。
- 新的索引不再支持老式的父/子索引,而是应该使用join字段。
- _default_映射类型也去掉了。
- 在6.8中,索引创建、索引模板和映射api支持一个查询字符串参数(include_type_name),它表示请求和响应是否应该包含类型名。它默认为true,应该设置为一个显式值以准备升级到7.0。不设置include_type_name将导致deprecation警告。没有显式类型的索引将使用虚拟类型名_doc。
Elasticsearch 7.x
- 不建议在请求中指定类型。比如,为文档建立索引不再需要映射类型。新的索引APIs是PUT {index}/_doc/{id},用于显式的id, POST {index}/_doc用于自动生成的id。注意,在7.0中,_doc是路径的永久部分,表示端点名称而不是文档类型。
- 索引创建、索引模板和映射api中的include_type_name参数默认为false。设置该参数将导致deprecation警告。
- _default_映射类型也去掉了。
Elasticsearch 8.x
- 不再支持在请求中指定类型。
- include_type_name参数被移除。
Elasticsearch 5.6.0 之前
PUT twitter
{
"mappings": {
"user": {
"properties": {
"name": { "type": "text" },
"user_name": { "type": "keyword" },
"email": { "type": "keyword" }
}
},
"tweet": {
"properties": {
"content": { "type": "text" },
"user_name": { "type": "keyword" },
"tweeted_at": { "type": "date" }
}
}
}
}
PUT twitter/user/kimchy
{
"name": "Shay Banon",
"user_name": "kimchy",
"email": "shay@kimchy.com"
}
PUT twitter/tweet/1
{
"user_name": "kimchy",
"tweeted_at": "2017-10-24T09:00:00Z",
"content": "Types are going away"
}
GET twitter/tweet/_search
{
"query": {
"match": {
"user_name": "kimchy"
}
}
}
Elasticsearch 6.x
PUT users
{
"settings": {
"index.mapping.single_type": true
},
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text"
},
"user_name": {
"type": "keyword"
},
"email": {
"type": "keyword"
}
}
}
}
}
PUT tweets
{
"settings": {
"index.mapping.single_type": true
},
"mappings": {
"_doc": {
"properties": {
"content": {
"type": "text"
},
"user_name": {
"type": "keyword"
},
"tweeted_at": {
"type": "date"
}
}
}
}
}
创建索引
PUT /index-demo
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
}
创建映射
在索引中每个文档都包括了一个或多个field(一行记录中包含一个或多个字段),创建映射就是向索引库中创建field的过程,下边是document和field与关系数据库的概念的类比:
文档(Document)----------------Row 行记录(数据库记录)
字段(Field)-------------------Columns 列
上边讲的创建索引库相当于关系数据库中的数据库还是表?
如果相当于数据库就表示一个索引库可以创建很多不同类型的文档,这在ES中也是允许的。
如果相当于表就表示一个索引库只能存储相同类型的文档,ES官方建议 在一个索引库中只存储相同类型的文档。
PUT /index-test-type/_mapping/_doc
{
"properties": {
"type_id": {
"type": "long"
},
"type_name": {
"type": "text"
}
}
}
PUT /index-test-type/
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 2
}
},
"mappings": {
"properties": {
"type_id": {
"type": "long"
},
"type_name": {
"type": "text"
}
}
}
}
参考
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/removal-of-types.html