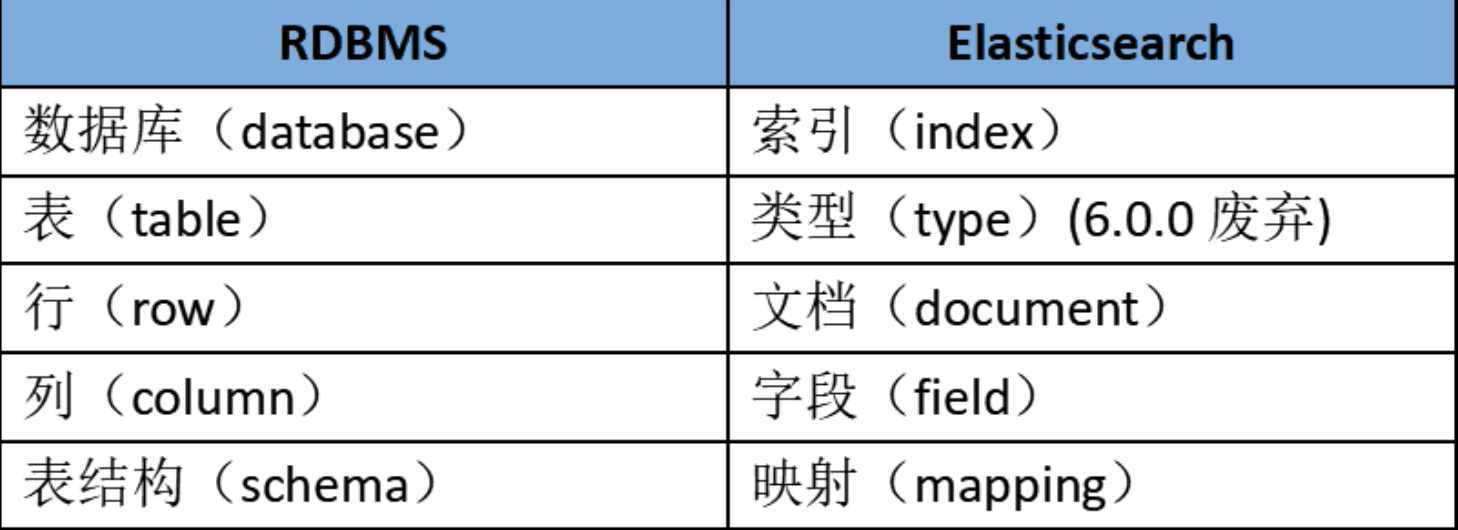
基本概念
Cluster 集群:由多个协同工作的 ES 实例组合成的集合,一个集群由一个唯一的名字标识
Node 节点:单个 ES 的服务实例叫做节点,本质上就是一个 Java 进程,存储集群的数据,参与集群的索引和搜索功能
- 主节点(Master)。主节点在整个集群是唯一的,Master 从有资格进行选举的节点(Master Eligible)中选举出来。主节点主要负责管理集群变更、元数据的更改
- 数据节点(Data Node)。其负责保存数据,要扩充存储时候需要扩展这类节点。数据节点还负责执行数据相关的操作,如:搜索、聚合、CURD 等。所以对节点机器的 CPU、内存、I/O 要求都比较高
- 协调节点(Coordinating Node)。负责接受客户端的请求,将请求路由到对应的节点进行处理,并且把最终结果汇总到一起返回给客户端。因为需要处理结果集和对其进行排序,需要较高的 CPU 和内存资源
Index 索引: 一个索引是一个文档的集合。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引
Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、商品数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据
Document 文档:被索引的一条数据,索引的基本信息单元,以JSON格式来表示
Shard 分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。分片的好处是允许我们水平切分/扩展容量可在多个分片上进行分布式的、并行的操作,提高系统的性能和吞吐量
Replication 备份: 一个分片可以有多个备份(副本)
关系数据库和elasticsearch对比如下
索引操作
数据类型
简单数据类型
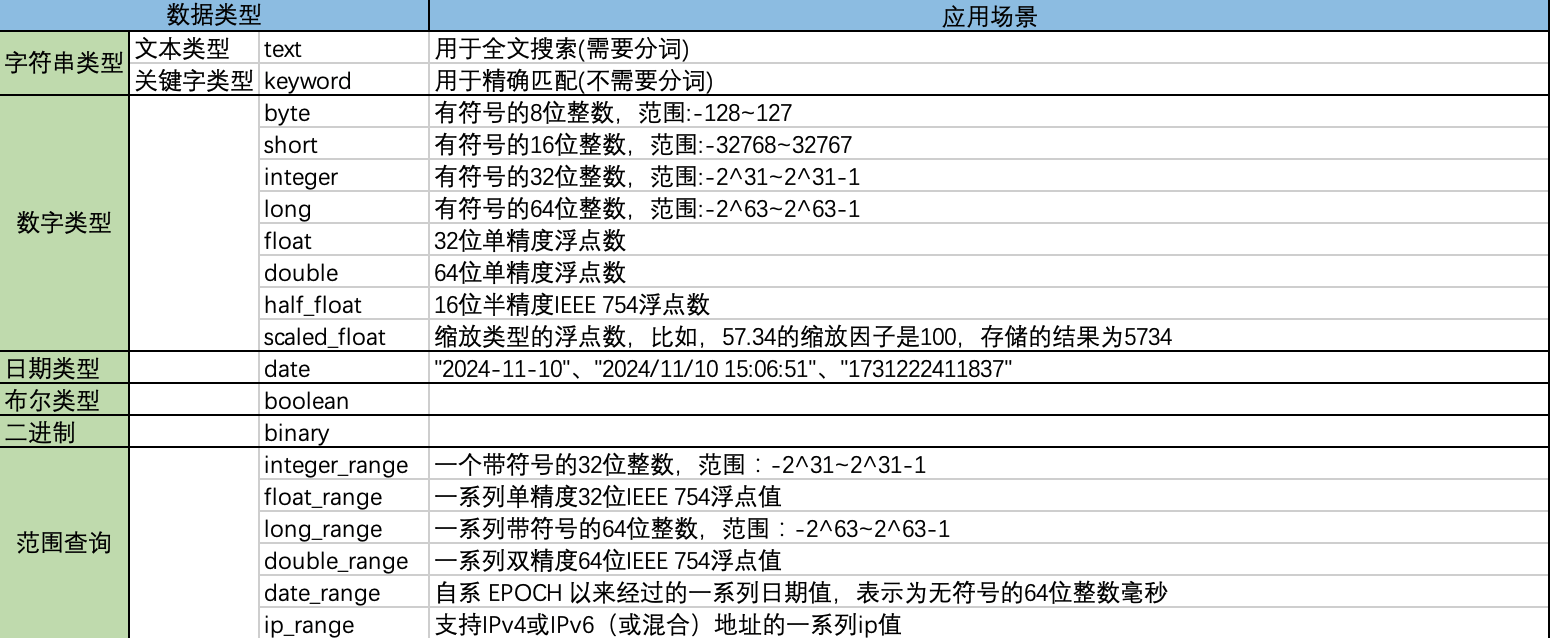
复杂数据类型
数据类型
- 字符串数组:["tom","jerry"]
- 整数数组:[1,2,3]
- 由数组组成的数组:[1,[2,3]],等价于[1,2,3]
- 对象数组:[{"name": "Tom", "age": 20}, {"name": "Jerry", "age": 18}]
注意:
- 动态添加数据时, 数组中第一个值的类型决定整个数组的类型
- 不支持混合数组类型, 比如[1, “abc”]
- 数组可以包含null值, 空数组[]会被当做missing field —— 没有值的字段
对象类型
{
"name": "tom",
"address": {
"region": "China",
"location": {"province": "ZheJiang", "city": "HangZhou"}
}
}
嵌套类型
嵌套类型是对象类型的特例,可以让array类型的对象被独立索引和搜索
如果需要对以对象进行索引, 且保留数组中每个对象的独立性, 就应该使用嵌套数据类型
# 创建文档
{
"group": "stark",
"performer": [
{"first": "John", "last": "Snow"},
{"first": "Sansa", "last": "Stark"}
]
}
搜索
{
"query": {
"nested": {
"path": "performer",
"query": {
"bool": {
"must": [
{ "match": { "performer.first": "John" }},
{ "match": { "performer.last": "Snow" }}
]
}
}
}
}
}
特殊类型
地理形状类型 、IP类型等等
创建索引
创建索引
PUT /my_index
{
# settings
# mappings
}
setting设置
{
"settings": {
# 主分片数
"number_of_shards": 5,
# 副本分片数
"number_of_replicas": 1,
# 设置一些过滤器
"analysis": {
# keyword类型搜索忽略大小写
"normalizer": {
"lowercase_normalizer": {
"type": "custom",
"char_filter": [],
"filter": [
"lowercase"
]
}
}
}
},
"mappings": {}
}
mapping设置
Dynamic Mapping自动创建mapping
分词
常用分词器
- Standard Analyzer : 这个是默认的分词器,使用 Unicode 文本分割算法,将文本按单词切分并且转为小写
- Simple Analyzer : 按照非字母切分并且进行小写处理
- Stop Analyzer : 与 Simple Analyzer 类似,但增加了停用词过滤(如 a、an、and、are、as、at、be、but 等)
- Whitespace Analyzer : 使用空格对文本进行切分,并不进行小写转换
- Patter n Analyzer : 使用正则表达式切分,默认使用 \W+ (非字符分隔)。支持小写转换和停用词删除
- keyword Analyzer : 不进行分词
- Language Analyzer : 提供了多种常见语言的分词器。如 Irish、Italian、Latvian 等
- Customer Analyzer:自定义分词器
IK 分词器
IK 的算法是基于词典的,其支持自定义词典和词典热更新。IK 分词器插件一定要和es的版本相对应,具体安装参考 https://github.com/infinilabs/analysis-ik
IK 有两种模式:ik_max_word 和 ik_smart
- ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌”,会穷尽各种可能的组合
- ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、国歌”,适合 Phrase 查询
测试分词器
POST _analyze
{
"analyzer": "ik_max_word",
"text": "Linus 在90年代开发出了linux操作系统"
}
POST _analyze
{
"analyzer": "ik_smart",
"text": "Linus 在90年代开发出了linux操作系统"
}
创建索引执行分词器
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
分词工作流程

- character filters: 对输入进行预处理,比如删除 html 元素、将表情符号映射为文本
- tokenizer: 按照指定的规则对文本进行切分,比如按空格来切分单词,同时也负责标记出每个单词的顺序、位置以及单词在原文本中开始和结束的偏移量
- token filters: 对切分后的单词进行处理,如转换为小写、删除停用词、增加同义词、词干化等。例如输入 Is this déja vu, 如果按照空格分词的话,会被分为 Is, this, déja, vu。我们可以设置 asciifolding token filters, 将 déja, 转换为 deja,lowercase将大写转换为小写
{
"char_filter": ["html_strip",
{
"type": "mapping",
"mappings": [
"😊 => happy"
]
}
],
"tokenizer": {
"type": "standard"
},
"filter": [],
"text": [
"Tom & Jerrey < <b>world</b> 😊"
]
}
{
"mappings": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"html_strip",
"emo_to_word"
],
"tokenizer": "standard",
"filter": [
"lowercase"
]
}
},
"char_filter": {
"emo_to_word": {
"type": "mapping",
"mappings": [
"😊 => happy"
]
}
}
}
}
}
什么是倒排索引
倒排索引指的是将每一个关键字映射到它出现的文档中。如下图所示
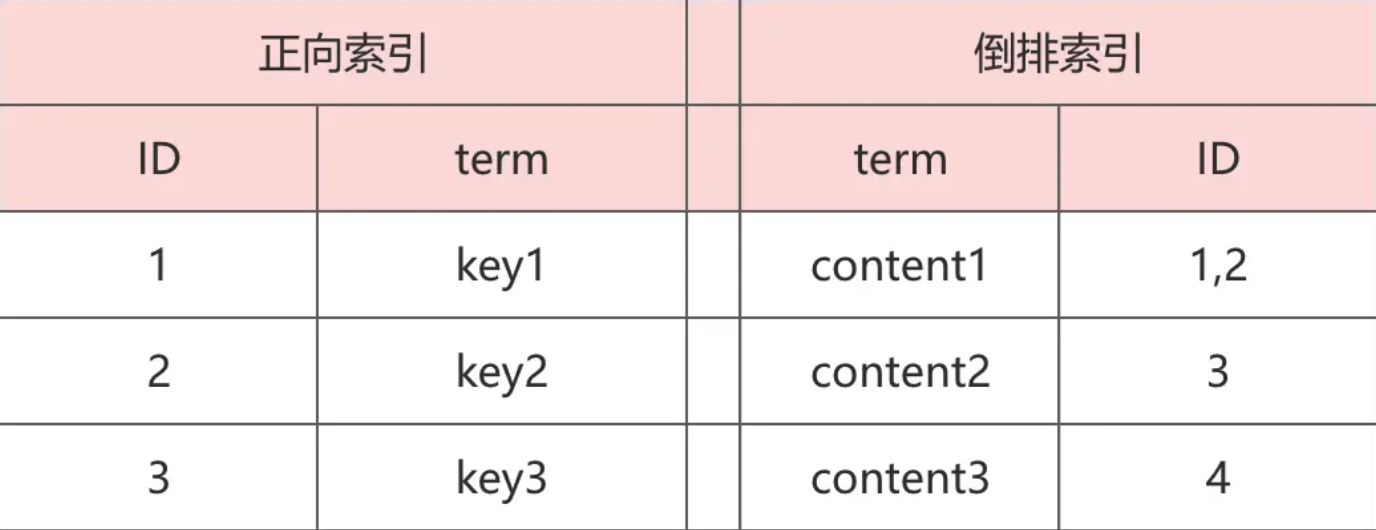
倒排索引数据结构
倒排索引分为 2 部分:一部分叫 term directory(term 词典),一部分叫 posting list(倒排列表)。如下图所示
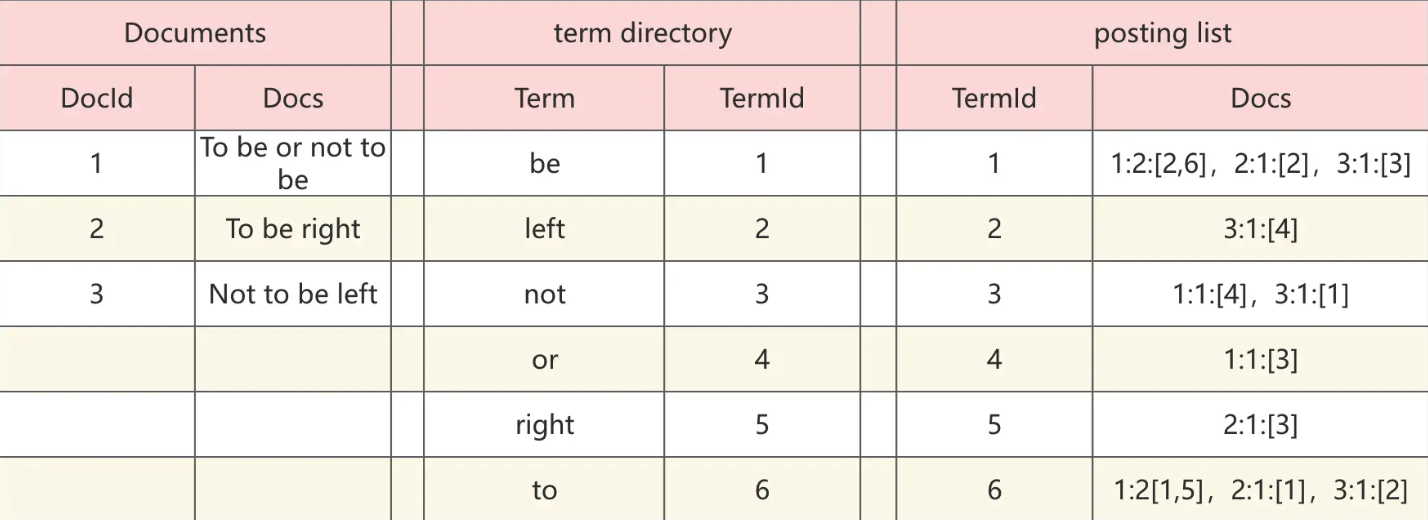
- term directory,term 字典,存放着每个单词到对应倒排列表的映射关系
- posting list,Docs 是一个数组。其中 1:2:[2,6] 意思如下
- 1:文档ID
- 2:词频(term frequency)
- [2,6]:出现在文档中的第 2,6 个 term
倒排索引的生成
这里涉及到我们之前讲过的分词器。工作流程如下图所示
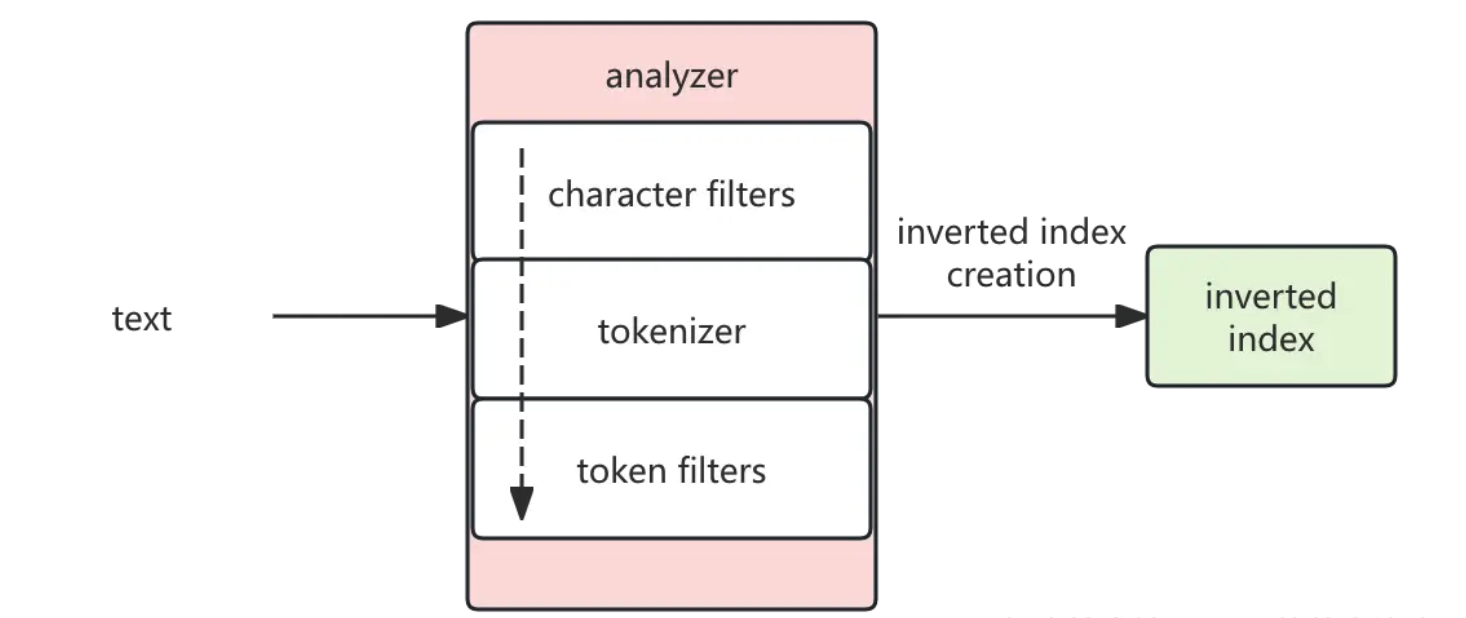
大体就包含2部分,根据分词器将文本分词,然后根据分词生成倒排索引。
查询
例如我们查询:To do right 则该文本会先被分词为:to, do, right 对应的结果如下图所示:
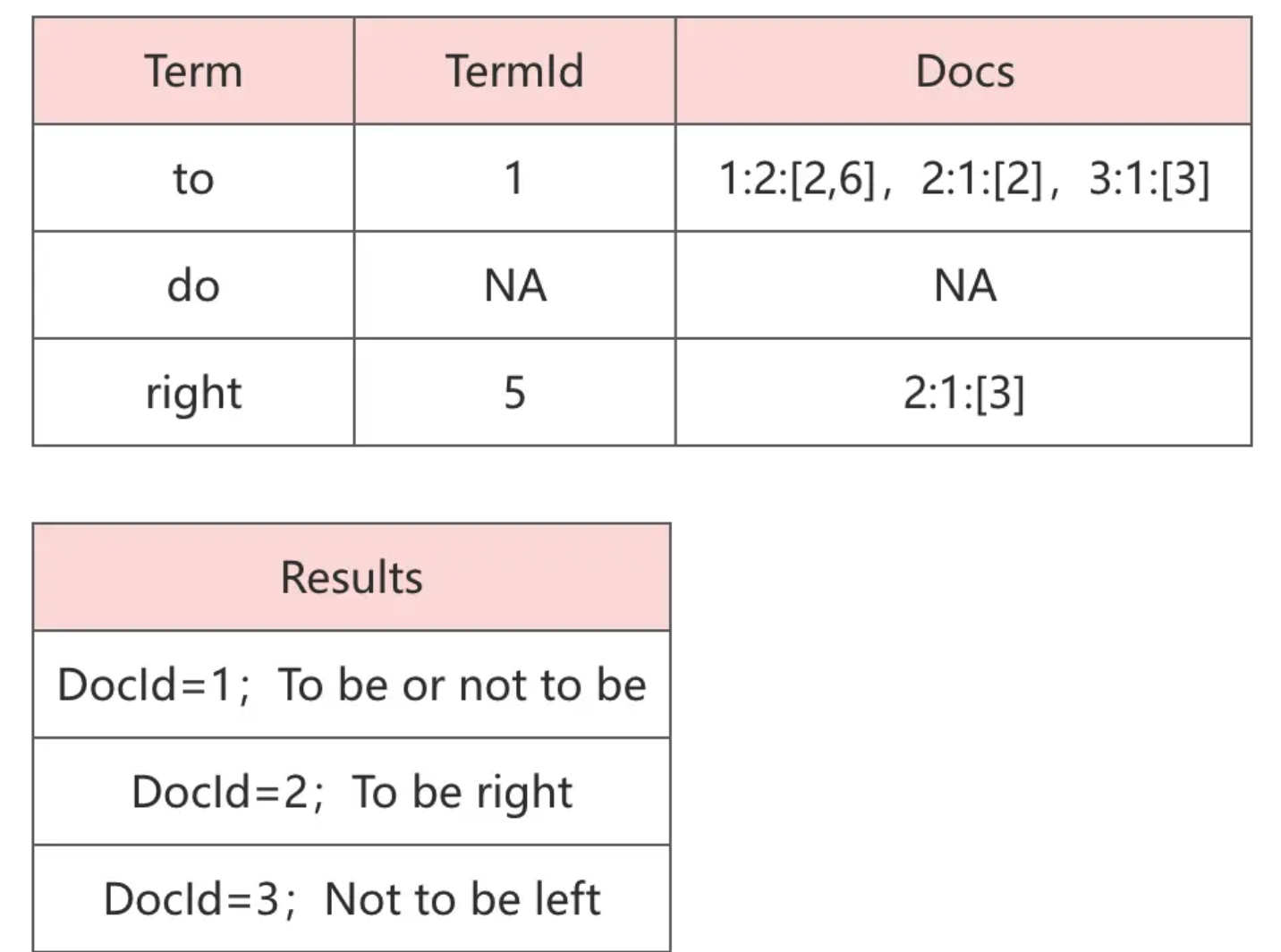
TF、IDF
默认情况下,ES 会根据文档与搜索词的相关性得分对结果降序返回。相关性得分与以下 2 个概念有关
- Term Frequency(TF):term 在文档中出现的频率,得分正相关。出现频率越高,得分越高
- Inverted Document Frequency(IDF):term 在 所有文档 中出现的频率,得分负相关。出现频率越高,得分越低
ES5之前默认的算分采用TF-IDF,ES5之后采用BM25
BM25是在TF-DF基础上做了一个收敛,避免了TF无限增长时得分无限增长的问题
搜索语法
match_all 查询所有文档
{
"query": {
"match_all": {}
}
}
match 单个字段匹配
单个字段的查询,先对搜索词进行分词,然后再搜索。
keyword:不分词精确匹配
text:分词后匹配
{
"query": {
"match": {
"title": "数据库", # text的会匹配"数据库"、"数据"...
}
}
}
multi_match 多字段匹配
为能在多个字段上反复执行相同查询提供了一种便捷方式
keyword:不分词精确匹配
text:分词匹配
Type:
- 最佳字段(best_fields):取fields中分数最高的,侧重于字段维度,单个字段的得分权重大,对于同一个query,单个field匹配更多的term,则优先排序。
- 混合字段(cross_fields):类似于copy_to,就是类似于把所有字段文字都拼接起来,然后算评分
{
"query": {
"multi_match": {
"type": "best_fields", # 取fields中最高的评分
"query": "数据库",
"fields": ["title","content"]
}
}
}
{
"query": {
"multi_match": {
"type": "cross_fields", # fields中字段全部拼接到一起算分
"operator": "and"
"query": "数据库",
"fields": ["title^5","content"], # 与copy_to相比,其优势是可以在搜索时为单个字段提升权重
}
}
}
match_phrase 短语匹配
短语匹配查询,slop表示分词的跨度,指分词和分词之间可以相隔多少个词,缺失了这些词仍然可以查到结果
{
"query": {
"match_phrase": {
"title": {
"query": "数据库",
"slop": 4
}
}
}
}
term 单值精确查询
单个字段的精确查询
keyword:不分词精确匹配
text:不分词匹配
如果是keyword类型查询的时候,不需要指定keyword关键字。如果是text类型的在全匹配的时候需要指定keyword关键字
{
"query": {
"term": {
"title": "红楼梦"
}
}
}
{
"query": {
"term": {
"content.keyword": "当时社会的阶级关系和权力结构"
}
}
}
# 大小写不敏感查询
{
"query": {
"term": {
"title": {
"value": "Romeo",
"case_insensitive": true
}
}
}
}
terms 多值精确匹配
精确匹配多个值,只要被查字段包含指定数组中任何一个值就算符合条件,不能设置大小写敏感, 如果需要大小写不敏感需要在创建索引时指定
{
"query": {
"terms": {
"title": ["红楼梦","西游记"]
}
}
}
prefix 前缀匹配
匹配符合前缀要求的倒排索引数据。
注意:需要区分大小写,搜索词要是小写(或者定义mapping和settings的时候给这个字段设置忽略大小写),因为文档的词都是小写的
{
"query": {
"prefix":{
"title":"rom"
}
}
}
wildcard 通配符匹配
通配符(*表示任何字符串,?表示任何单个字符)匹配倒排索引
注意:需要区分大小写,搜索词要是小写(或者定义mapping和settings的时候给这个字段设置忽略大小写),因为文档的词都是小写的
{
"query": {
"wildcard": {
"title": "ro*"
}
}
}
regexp 正则匹配
正则表达式匹配倒排索引
注意:需要区分大小写,搜索词要是小写(或者定义mapping和settings的时候给这个字段设置忽略大小写),因为文档的词都是小写的
{
"query": {
"regexp": {
"title": ".*iet"
}
}
}
fuzzy 近似匹配
fuzziness用于控制levenshtein距离,区分大小写
{
"query": {
"fuzzy": {
"author": {
"value": "Shakespea",
"fuzziness": 2
}
}
}
}
range 区间匹配
区间匹配,
可以使用:gt(大于)、gte(大于等于)、lt(小于)、lte(小于等于)
{
"query": {
"range": {
"count": {
"gte": 30,
"lte": 70
}
}
}
}
exists 匹配指定字段非空的文档
查询指定字段值不为null的数据,用于把某个字段不为null的文档往前排
{
"query": {
"exists": {
"field": "title"
}
}
}
ids id数值匹配
用于通过文档id数组匹配文档
{
"query": {
"ids": {
"values": [1,3]
}
}
}
term、match 区别
- term 完整匹配整个输入,正常 term 的查询性能会优于 match
- match 对输入进行分词,然后匹配每个分词(需要注意的是,当在 keyword 类型下使用 match 时,他的表现和 term 一样)
bool 布尔查询
bool查询是一个或者多个查询子句的组合,支持must 、must not、should、filter四种子句。
- must :必须匹配,参与算分
- should :选择性匹配、参与算分
- must not:必须不匹配,不参与算分
- filter:必须匹配,不参与算分, 可以使用缓存
bool子查询可以任意顺序出现、可以同时多个子查询
should must联用问题
{
"query": {
"bool": {
"must": {
"term": {"gender": "男"}
},
"should": [
{
"term": {"score": 70}
},
{
"term": {"score": 80}
}
]
}
}
}
解决方法
{
"query": {
"bool": {
"should": [
{
"bool": {
"must": [
{
"term": {"gender": "男"}
},
{
"term": {"score": "70"}
}
]
}
},
{
"bool": {
"must": [
{
"term": {"gender": "男"}
},
{
"term": {"score": "80"}
}
]
}
}
]
}
}
}
{
"query": {
"bool": {
"must": [
{
"term": {"gender": "男"}
},
{
"bool": {
"should": [
{
"term": {"score": 70}
},
{
"term": {"score": 80}
}
]
}
}
]
}
}
}
尽量在筛选的时候多使用不参与算分的must_not和filter,以保证性能良好
query_string 字符串匹配
字符串的专用匹配,可以多个条件、多个字段进行匹配
- 逻辑运算符大写AND、OR、NOT
- 默认会对字符串分词,如果不需要分词 需要加上”“
- 默认运算符是OR
- 严格按照逻辑关系加括号
{
"query": {
"query_string": {
"query": "(truth AND good) OR Romeo",
"fields": ["title","content"]
}
}
}
分页
ES 提供了 3 种分页方式:
- from + size:最普通、简单的分页方式,但是会产生深分页的问题
- search after:解决了深分页的问题,但只能一页一页地往下翻,不支持跳转到指定页数
- scroll API/PIT:会创建数据快照,无法检索新写入的数据,适合对结果集进行遍历的时候使用
from + size 分页操作与深分页问题
在我们检索数据时,系统会对数据按照相关性算分进行排序,然后默认返回前 10 条数据。我们可以使用 from + size 来指定获取哪些数据。其使用示例如下:
{
"from": 0, # 指定开始位置
"size": 10, # 指定获取文档个数
"query": {
"match_all": {}
}
}
如上示例,使用 "from" 指定获取数据的开始位置,使用 "size" 指定获取文档的个数。
但当我们将 from 设置大于 10000 或者 size 设置大于 10001 的时候,这个查询将会报错:
# 返回结果中的部分错误信息
......
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Result window is too large, from + size must be less than or equal to: [10000] but was [10001]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
],
"type" : "search_phase_execution_exception",
"reason" : "all shards failed",
"phase" : "query",
"grouped" : true,
......
数据集合太大了,系统拒绝了我们的请求。我们可以使用 "index.max_result_window" 配置项设置这个上限:
PUT my_index/_settings
{
"index": {
"max_result_window": 20000
}
}
这个配置有时候可以解决燃眉之急,但是这个上限设置过大的情况下会产生非常严重的后果。
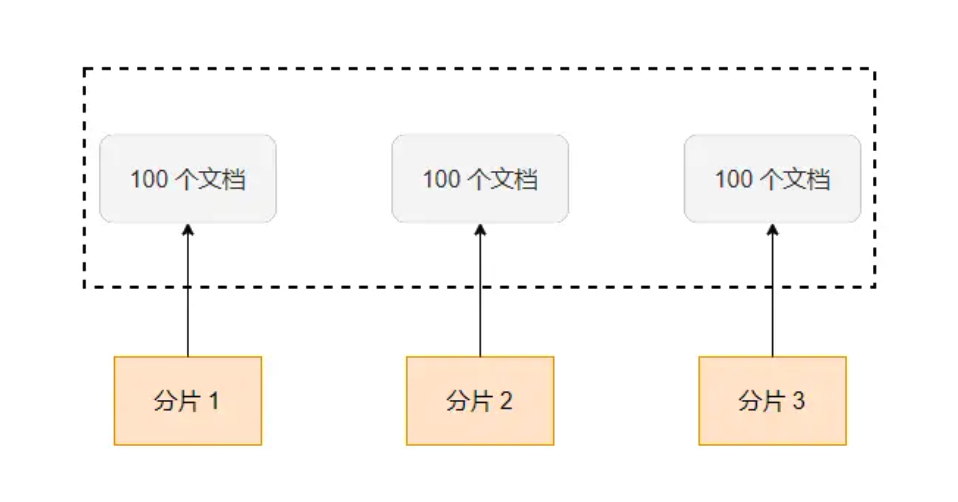
如上图,ES把数据保存到3个主分片中,当使用from = 90和size = 10进行分页的时候,ES会先从每个分片中分别获取100个文档,然后把这300个文档再汇聚到协调节点中进行排序,最后选出排序后的前100个文档,返回第90到99的文档。
可以看到,当页数变大(发生了深分页)的时候,在每个分片中获取的数据就越多,消耗的资源就越多。并且如果分片越多,汇聚到协调节点的数据也越多,最终汇聚到协调节点的文档数为:shard_amount * (from + size)。
search after
使用 search after API 可以避免产生深分页的问题,不过 search after 不支持跳转到指定页数,只能一页页地往下翻。
使用 search after 接口分为两步:
- 在 sort 中指定需要排序的字段,并且保证其值的唯一性(可以使用文档的 ID)
- 在下一次查询时,带上返回结果中最后一个文档的 sort 值进行访问
# 第一次调用 search after
POST my_index/_search
{
"size": 2,
"query": { "match_all": {} },
"sort": [
{ "_id": "asc" }
]
}
# 返回结果
"hits" : [
{
"_id" : "1",
"_source" : {
"book_id" : "4ee82467",
"price" : 20.9
},
"sort" : ["1"]
},
{
"_id" : "2",
"_source" : {
"book_id" : "4ee82462",
"price" : 19.9
},
"sort" : ["2"]
}
]
# 第二次调用 search after
POST books/_search
{
"size": 2,
"query": {
"match_all": {}
},
"search_after":["2"], # 设置为上次返回结果中最后一个文档的 sort 值
"sort": [
{ "_id": "asc" }
]
}
因为有了唯一的排序值做保证,所以每个分片只需要返回比 sort 中唯一值大的 size 个数据即可。例如,上一次的查询返回的最后一个文档的 sort 为 a,那么这一次查询只需要在分片 1、2、3 中返回 size 个排序比 a 大的文档,协调节点汇总这些数据进行排序后返回 size 个结果给客户端。
scroll API
当我们想对结果集进行遍历的时候,例如做全量数据导出时,可以使用 scroll API。scroll API 会创建数据快照,后续的访问将会基于这个快照来进行,所以无法检索新写入的数据。
# 第一次使用 scroll API
POST my_index/_search?scroll=10m
{
"query": {
"match_all": {}
},
"sort": { "price": "desc" },
"size": 2
}
# 结果
{
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF9......==",
"hits" : {
"hits" : [
{
"_id" : "6",
"_source" : {
"book_id" : "4ee82467",
"price" : 20.9
}
},
......
]
}
}
如上示例,在第一次使用 scroll API 时需要初始化 scroll 搜索并且创建快照,使用 scroll 查询参数指定本次“查询上下文”(快照)的有效时间,本示例中为 10 分钟
# 进行翻页
POST /_search/scroll
{
"scroll" : "5m",
"scroll_id" : "FGluY2x1ZGVfY29udGV4dF9......=="
}
我们把上一次返回结果中的 _scroll_id 值放到本次请求的 scroll_id 字段中,并且指定“查询上下文”的有效时间为 5 分钟。同样此次的返回结果也会带有新的 _scroll_id。
scroll 问题
https://discuss.elastic.co/t/ridiculously-long-scroll-id/12913
PIT
ES 7.10 中引入了 Point In Time 后,scroll API 就不建议被使用了。Point In Time(PIT)是 ES 7.10 中引入的新特性,PIT 是一个轻量级的数据状态视图,用户可以利用这个视图反复查询某个索引,仿佛这个索引的数据集停留在某个时间点上。也就是说,在创建 PIT 之后更新的数据是无法被检索到的。
当我们想要获取、统计以当前时间节点为准的数据而不考虑后续数据更新的时候,PIT 就显得非常有用了。使用 PIT 前需要显式使用 _pit API 获取一个 PID ID:
# 使用 pit API 获取一个 PID ID
POST /my_index/_pit?keep_alive=20m
# 结果
{
"id": "46ToAwMDaWR5BXV1aWQy......=="
}
如上示例,使用 _pit 接口获取了一个 PIT ID,keep_alive 参数设置了这个视图的有效时长。有了这个 PIT ID 后续的查询就可以结合它来进行了
PIT 可以结合 search after 进行查询,能有效保证数据的一致性。 PIT 结合 search after 的流程与前面介绍的 search after 差不多,主要区别是需要在请求 body 中带上 PIT ID,其示例如下
# 第一次调用 search after,因为使用了 PIT,这个时候搜索不需要指定 index 了。
POST _search
{
"size": 2,
"query": { "match_all": {} },
"pit": {
"id": "46ToAwMDaWR5BXV1aWQy......==", # 添加 PIT id
"keep_alive": "5m" # 视图的有效时长
},
"sort": [
{ "price": "desc" } # 按价格倒序排序
]
}
# 结果
{
"pit_id" : "46ToAwMDaWR5BXV1aWQy......==",
"hits" : {
"hits" : [
{
"_id" : "6",
"_source" : {
"book_id" : "4ee82467",
"price" : 20.9
},
"sort" : [20.9, 8589934593]
},
{
"_id" : "1",
"_source" : {
"book_id" : "4ee82462"
"price" : 19.9
},
"sort" : [19.9, 8589934592]
}
]
}
}
在 pit 字段中指定 PIT ID 和设置 keep_alive 来指定视图的有效时长。需要注意的是,使用了 PIT 后也不需要在路径中指定索引名称了
在其返回结果中,sort 数组中包含了两个元素,其中第一个是我们用作排序的 price 的值,第二个值是一个隐含的排序值。所有的 PIT 请求都会自动加入一个隐式的用于排序的字段称为:_shard_doc,当然这个排序值可以显式指定。这个隐含的字段官方也称它为:tiebreaker(决胜字段),其代表的是文档的唯一值,保证了分页不会丢失或者分页结果的数据不会重复,其作用就好像原 search after 的 sort 字段中要指定的唯一值一样。
在进行翻页的时候和原 search after 一样,需要把上次结果中最后一个文档的 sort 值带上:
# 第二次调用 search after,因为使用了 PIT,这个时候搜索不需要指定 index 了。
POST _search
{
"size": 2,
"query": {
"match_all": {}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQy......==", # 添加 PIT id
"keep_alive": "5m" # 视图的有效时长
},
"search_after": [19.9, 8589934592], # 上次结果中最后一个文档的 sort 值
"sort": [
{ "price": "desc" }
]
}
常见问题
精确匹配
忽略大小写
text的创建文档时是会分词并且转成小写的,但是精确匹配keyword是不分词的,也不会转成小写。有时候我们想要忽略大小写的精确匹配
需要在创建索引的时候,设置忽略大小写
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 0,
# 1、指定忽略大小写
"analysis": {
"normalizer": {
"lowercase_normalizer": {
"type": "custom",
"char_filter": [],
"filter": [
"lowercase"
]
}
}
}
},
"mappings": {
"tag": {
"type": "keyword",
# 2、设置忽略大小写
"normalizer": "lowercase_normalizer"
}
}
}
使用case_insensitive,仅支持term
{
"query": {
"term": {
"title": {
"value": "Romeo",
"case_insensitive": true
}
}
}
}
分词技巧
索引时用ik_max_word(最细粒度划分),在搜索时用ik_smart(最少切分) 即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
{
"query": {
"match": {
"title": {
"analyzer": "ik_smart",
"query": "文章"
}
}
}
}
返回数据具体总条数
track_total_hits参数默认为false,为false时,当搜索到的数据>10000条,则只显示10000条,为true时,可以显示详细条数
返回指定字段
不是所有字段都需要返回,可以指定需要返回的字段
可以使用通配符*
{
"from": 0,
"size": 1,
"query": {},
"_source": {
# 指定返回字段
"includes": [
"title"
],
# 指定不返回字段
"excludes": ["name","bir*"]
}
}
copy_to
Elasticsearch允许在映射中为某个字段定义copy_to参数,以实现复制多个其他字段的内容,这样在搜索一个字段时能够达到同时搜索多个字段的效果,使用字段复制比使用多字段匹配Multi_match性能更好。
{
"mappings": {
"properties": {
"title": {
"type": "text",
"copy_to": "titleBrief" # 指定copy_to
},
"brief": {
"type": "text",
"copy_to": "titleBrief" # 指定copy_to
}
}
}
}
{
{
"query": {
"match": {
"titleBrief": "红"
}
}
}
}
执行性能
Profile API 用于查看 DSL 性能瓶颈。只需要添加 "profile": true 即可查看 DSL 的执行性能
{
"profile": true,
"query": {
"query_string": {
"query": "tag:(taga) AND tag_type:(A OR b) AND user:(173)"
}
}
}
Suggester API搜索提示
ES提供了suggseter api,提供了4种类型的suggseters:Term Suggester(基于单词的纠错补全)、Phrase Suggester(基于短语的纠错补全)、Complete Suggester(自动补全单词,输入词语的前半部分,自动补全单词)、Context Suggseter(基于上下文的补全提示,可以实现上下文感知推荐)
Term Suggester
将输入的文本分解为Token,然后在索引的字段里查找相似的term返回
{
"query": {
"match": {
"database": "posgresql"
}
},
"suggest": {
"my-term-suggestion": {
"text": "posgresql",
"term": {
"suggest_mode": "missing",
"field": "database"
}
},
"my-term-suggestion2": {
"text": "oracla",
"term": {
"suggest_mode": "missing",
"field": "database"
}
}
}
}